Notre article sur les caches http vous a expliqué comment fonctionnait le mécanisme de cache, et les échanges entre client et serveur associés.
Nous y avions également évoqué le fonctionnement du mécanisme d’ETag. Voyons aujourd’hui comment le mettre en place dans notre application ruby on rails.
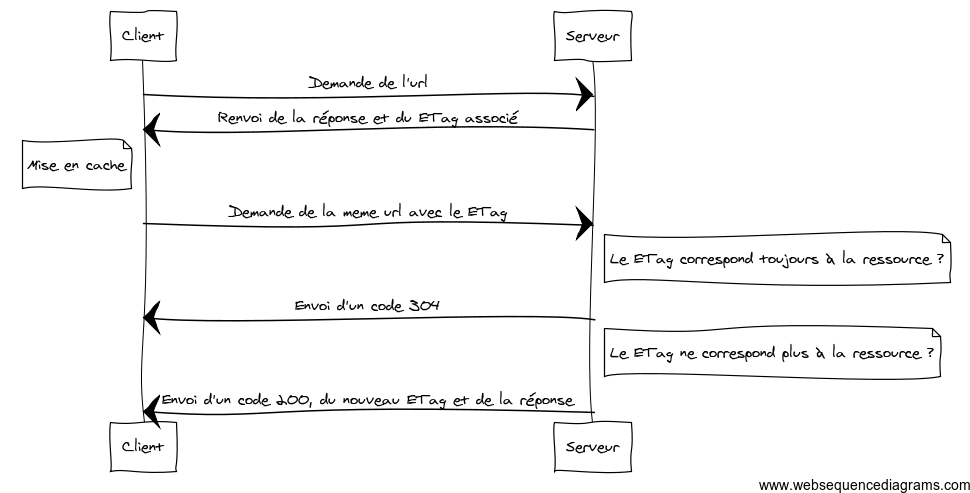
Le principe d’un ETag est d’associer un identifiant à une ressource HTTP, typiquement une URL. Généralement cet identifiant correspond à un hash.
Ce hash est relatif au contenu que sert la ressource HTTP, de telle sorte qu’il change si la ressource fournie change également.
Quand le client va interroger le serveur il va demander l’URL en fournissant également le ETag qu’il possède. Le serveur va vérifier que le ETag fourni correspond toujours à la ressource actuelle. Si c’est le cas, il va simplement renvoyer un code 304 pour lui signifier qu’il peut utiliser sa version en cache car elle est à jour.
Autrement il fournit le nouvel ETag et son contenu.
Nous allons créer une application simple basée sur un scaffold de produit:
bin/rails g scaffold products title description:text price:decimal active:boolean
Voilà la tête de notre action show:
class ProductsController < ApplicationController
before_action :set_product, only: [:show, :edit, :update, :destroy]
# GET /products/1
# GET /products/1.json
def show
end
end
Dès lors que vous avez en place un contrôleur classique, un entête ETag est déjà envoyé par le serveur avec votre réponse, par contre il n’est pas exploité en l’état.
Pour mettre en place la gestion du ETag c’est aussi simple que :
def show
fresh_when(@product)
end
Dès lors notre contrôleur va renvoyer une 304 si la ressource n’a pas changée.
L’intérêt est que vous n’avez pas à gérer manuellement l’invalidation du cache et la gestion du ETag. En effet dès lors que vous modifiez votre objet, par exemple :
product = Product.last
product.update_attributes title: "Reload"
le ETag va changer, le serveur enverra à nouveau une 200 et votre nouvelle ressource sera cachée par le client.
Ce système est vraiment pratique, car transparent, mais il a ses défauts. D’une part si vous
mettez à jour l’objet directement en base, que ça soit par le biais d’un script tiers,
ou d’un update_column(s) le ETag associé à votre objet ne changera pas.
D’autre part ce couplage entre ETag et objet ne permet pas d’invalider le cache en cas de modification de la vue.
Si par exemple vous modifiez une balise, cela ne sera pas pris en compte.
Si vous souhaitez réaliser des traitements si votre objet est périmé vous pouvez utiliser stale?
def show
if stale?(@product)
@product.compute_values
respond_to do |format|
format.html
end
end
end
Que ce soit stale? ou fresh_when vous pouvez passer 3 options, le etag, si vous voulez spécifier sur quel objet le calculer, le last_modified, qui par défaut utilisera le updated_at
de l’objet s’il existe et enfin public.
Par défaut le cache est privé, ce qui empêche les intermédiaires entre client et serveur de mettre en cache la ressource (un proxy par exemple).
Si votre ressource HTTP ne contient que des informations publiques vous pouvez l’utiliser.
Depuis Rails 4 vous pouvez spécifier un bloc pour l’ensemble de votre contrôleur.
C’est très commode dans le cas ou vos URL renvoient des contenus différents selon les cas. L’exemple le plus fréquent est celui de la gestion de l’utilisateur courant.
Sur les différentes actions, on voudra générer un ETag différent d’un utilisateur à l’autre afin de s’assurer qu’un utilisateur non identifié ne puisse accéder à une page en cache.
etag { current_user.try :id }
Il est parfaitement possible de cumuler les bloc etag {}.
etag { current_user.try :id }
etag do
{ customer_id: current_customer.id } if %w(index edit).include?(params[:action])
end
Tout d’abord il faut préciser que la gestion est différente entre Rails 3 et Rails 4.
En rails 3 c’est un hash du body qui était produit en tant que contenu du ETag. L’avantage est que la modification de la vue était bien répercutée sur le ETag, on pouvait donc en modifier le code sans problème.
L’inconvénient était de devoir recalculer ce body à chaque fois. Au final on gagnait en données non transférées mais le serveur devait toujours fournir le même travail.
En Rails 4 en revanche, quand nous passons notre objet product à fresh_when, rails va faire l’équivalent de:
response.etag = @product
response.last_modified = @product.updated_at
Le setter etag peut prendre un tableau, qui correspond aux blocs définis dans le contrôleur.
Il faut savoir que chaque objet à sa propre clé de cache, que ce soit l’instance d’ActiveRecord, comme le modèle en lui même:
Product.model_name.cache_key
# products
product.cache_key
# "products/1-20131206092118622798000"
La chaîne de product correspond donc à la clé de cache du modèle suivi de l’id et du timestamp (colonne updated-at en UTC) de l’objet.
Enfin cette clé est hashée en md5:
Digest::MD5.hexdigest(key)
# f8ea69ebc103b48971a6ec1bd82af7ef
Rails 4 se base donc uniquement sur la clé de l’objet et non plus sur le contenu de la réponse. C’est beaucoup plus performant mais ça pose les problèmes de modification de la vue.
Vous vous demandez sûrement comment Rails fonctionne pour les collections.
En effet il n’y a pas de cache_key pour ActiveRecord::Relation.
Et bien rails, plus particulièrement ActiveSupport::Cache.expand_cache_key(object),
renvoie une concaténation des différentes clés des objets composant la collection.
Dans ce cas, si votre collection est triée dans votre vue, vous aurez besoin d’utiliser
vos paramètres de tri dans un bloc etag {}.
Le gros avantage du cache HTTP par le biais des ETag tient au fait qu’il est disponible de base. Vous n’avez pas d’installation complémentaire à réaliser.
Forcément, plus la page de base est lourde, plus ce cache est important.
Maintenant, comme tout système de cache, il doit être bien réfléchi et il sera relativement complexe à tester.
There are only two hard things in Computer Science: cache invalidation and naming things. — Tim Bray.
L’équipe Synbioz.
Libres d’être ensemble.
{kind=link}