

Nous sommes souvent confrontés au problème récurrent de l’entropie et l’érosion du code. Passé un certain stade, il devient très complexe et pénible d’ajouter des fonctionnalités ou correctifs.
La dette technique, notre ennemi de toujours, c’est sûrement elle qui se cache derrière ce complot. Non content de l’avoir identifiée et de connaitre quelques astuces pour vivre avec, nous recherchons activement des solutions techniques pour limiter l’impact de cette dette.
Si beaucoup d’applications restent simples et petites dans leur portée fonctionnelle, d’autres s’étoffent et se complexifient avec le temps, les équipes qui se succèdent, ou le besoin de compatibilité qui s’étend. Il devient très vite délicat de s’y retrouver, d’éviter les effets de bords en cascade, ou tout simplement de tester le dernier ajout.
Une bonne partie des problèmes peuvent être résolus par la mise en pratique d’hygiène de gestion de projet , mais ça ne reviendrait qu’à renforcer un seul maillon de toute une chaine. La solidité globale de la chaine restant toujours fonction de celle de son maillon le plus faible.
Ce n’est pas une situation irrémédiable, le prochain maillon de la chaîne auquel s’atteler c’est l’architecture du système. Il est possible d’investir dans l’avenir au présent, et d’adopter des pratiques qui peuvent solutionner les problèmes avant qu’ils n’apparaissent.
Comment dessiner l’architecture d’un système dont la complexité fonctionnelle est étendue, et bien plus profonde qu’une API qui expose le CRUD du modèle ? Sur quels points porter son attention, comment partitionner le code et ses responsabilités ?
C’est une série d’articles que nous vous proposons, elle commence par cette (longue) introduction qui pose le décor et initie à l’analyse du domaine du système.
Les difficultés apparaissent généralement après la phase de développement initiale, à la reprise d’un projet extérieur ou d’un changement d’équipe. Les dégâts sont déjà si avancés que bien souvent quelqu’un finit par lâcher le tristement célèbre « Il faut tout réécrire de zéro ».
Même si on n’en vient pas toujours à cette extrémité, ayons l’honnêteté d’avouer que c’est une situation qui arrive assez couramment dans notre industrie. Ce qui pénalise plus souvent le client que l’éditeur, malheureusement le client a rarement conscience de la dette technique.
Dans la liste des difficultés qui mènent a cette situation, voici un Hit Parade des plus évidentes.
Une des difficultés les plus évidentes avec une application fournie, c’est que cela demande une gymnastique mentale importante. Il est bien souvent impossible de garder l’ensemble de la structure du code, des fonctionnalités et de leurs impacts en tête. Et bien plus difficile encore quand on n’est pas l’auteur de l’intégralité du code.
Cela rend les développements longs et pénibles. Introduire une nouvelle tête dans l’équipe demandera beaucoup de temps.
Que fait mon application, ou commence et se termine une fonctionnalité ? Prenons l’exemple d’une application Rails touffue, voici ce qu’il arrive de trouver dans le répertoire app
app
├── assets
├── builders
├── business
├── computers
├── concerns
├── controllers
├── data_objects
├── decorators
├── exports
├── factories
├── fetchers
├── filters
├── forms
├── helpers
├── mailers
├── models
├── presenters
├── providers
├── uploaders
└── views
Une série de patterns… C’est donc la seule vision que l’on peut avoir de nos applications ? Impossible de savoir ce que fait l’application. En revanche on voit que tout une série de patterns ont été utilisés à plus ou moins bon escient.
Pour modifier une fonctionnalité, par exemple la manière dont s’affiche le nom des utilisateurs, comment s’orienter dans quelque chose d’aussi anonyme ? Il faut alors ouvrir chaque répertoire, sous répertoire, et fichier pour faire l’inventaire de tous les endroits où la fonctionnalité est référencée. Chaque petit morceau d’implémentation, méthode, configuration se trouve noyé dans une masse de patterns.
Chaque nom ci-dessus n’est pas le « quoi » , mais le « comment ». C’est quand même une curieuse manière d’organiser les choses.
Et dans le système de gestion de version du code ? Lors de l’implémentation d’une fonctionnalité le bruit des commits s’articulera autour des répertoires portant des noms de modules.
Posons-nous la question, quel est le coût de cette organisation, quels en sont les bénéfices ?
Une fonctionnalité vient d’être implémentée dans l’application, après tout un tas de micro-modifications dans une douzaine de fichiers dans la jungle de l’arborescence. Nous nous devons d’écrire quelques tests car nous sommes consciencieux.
La fonctionnalité est simplement une modification du format d’affichage du nom de l’utilisateur et de son rôle. Mais voilà, pour pouvoir tester cette modification fonctionnelle, il faut un serveur de base de données, instancier une série d’objets tous liés les uns aux autres avec des outils comme Factory Girl. Peut-être parce que ma méthode de calcul est directement implémentée sur un objet Active Record ; ou que la classe en charge de ce formatage s’appuie sur des méthodes Active Record pour récupérer des objets et leurs relations… Car oui le code est souvent fortement couplé et dépendant du framework choisi.
Un example simple de couplage de code:
<% User.where(active: true).each do |u| %>
<%= [u.first_name, u.last_name].join(' ') %>
<%= end %>
Ça ne choque peut-être personne, mais plusieurs problèmes sautent aux yeux :
Bien évidement cet exemple est simpliste mais il montre le couplage entre deux extrémités opposées de notre application. Il est facile d’imaginer que presque toutes les couches intermédiaires seront aussi impactées.
Englué dans du code fortement couplé, avec des tests fragiles, et rares car complexes à écrire. L’application monolithique ne permettant pas de raisonner sur de petits modules.
Nous serions bien en peine de la faire évoluer vers la nouvelle version du framework ou vers une base de données différente. Ou sinon au prix d’une réécriture complète. Les technologies qui supportent le développement des systèmes évoluent plus vite que le domaine de l’application (en règle générale). Ce qui plaide en la faveur d’un cœur de domaine stable, et isolé des technologies qui le supportent.
Migrer de framework ne se fait pas régulièrement. Mais si on regarde un peu plus large, les montées de version sont assez fréquentes. Et si l’on a l’intention de maintenir l’application sur plusieurs années, elles seront inévitables.
Pouvoir substituer les dépendances sans craindre de voir s’effondrer le métier en place, comme Martin Fowler le souligne dans l’article Sacrificial Architecture.
Qu’il s’agisse de distribuer le système sur plusieurs nœuds ou le développement sur plusieurs équipes, le couplage fort du code joue toujours en notre défaveur.
La livraison et la mise en production de systèmes fortement couplés nous posent aussi beaucoup de difficultés opérationnelles. Sur des systèmes composés de plusieurs services fortement couplés, il est difficile de ne pas avoir à interrompre ou mettre à jour plusieurs services.
Les écrits existent sur le sujet, certains semblent répondre aux problèmes exposés. En voici un résumé des grands principes.
Dans son livre «Object Oriented Software Engineering: A Use-Case Driven Approach», Ivar Jacobson prone comme le titre l’indique une approche du développement centré sur les use cases. Il y met l’accent sur le fait que les systèmes doivent être conçus en s’appuyant sur l’analyse des use cases business.
Il propose de transposer ceux-ci dans l’architecture du code au travers d’un pattern appelé Boundary Control Entity. Qui est au MVC ce que le Canada Dry est à l’alcool. Ça y ressemble mais ça n’en est pas du tout.
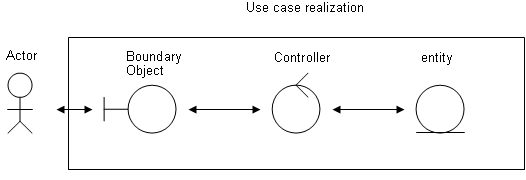
Partant d’un use case, il existe un actor , qui est un objet externe au use case. L’actor peut être un utilisateur, un système, un périphérique… Il s’agit principalement d’un rôle par exemple acheteur, vendeur, afficheur, notifiant… mais pas bob, HTML ni SMS… C’est lui qui interagit avec le système en passant au travers du boundary en envoyant ou recevant des messages.
Les boundaries formalisent l’échange entre les actors, et les controls , Ils sont l’API du use case. Les controls en fonction des données transmises au travers des boundaries, manipulent les entities qui sont les objets du domaine métier.
Enfin quelques règles pour consolider le tout :
Donc ça n’a rien à voir avec la structure triangulaire l’un MVC. Il propose une isolation forte entre les différentes couches, et un séparation des responsabilités.
En 2007 Alistair Cockburn propose un modèle d’architecture, Hexagonal, qui vise à isoler le métier de l’application du reste du monde. Le code métier réside au centre, et pour chaque acteur externe au business, implémente un port. Pour chaque port il peut exister plusieurs adaptateurs, qui permettent d’interchanger mocks et différentes implémentations.
Le résultat est un système aisément testable, et isolé des dépendances externes. Il est également question d’une approche centrée sur les use cases, celle-ci permet d’identifier rapidement les acteurs extérieurs et de définir les boundaries.
Jeffrey Pallermo en 2008 présente un patron architectural qui place le domaine métier au centre de l’application, Le domain model représente les structures de données et les règles métier du SUD (System Under Design) , il n’a aucune dépendance excepté lui-même. Il est une dépendance de la couche domain services chargée d’orchestrer les échanges avec des services externes et la persistance le plus souvent sous forme d’une interface pour le repository pattern. Ensuite vient la couche application services qui se charge d’orchestrer la danse du domain model des domain services pour lier le tout dans un fonctionnement applicatif. Les parties tests, interfaces et base de données utilisent les interfaces définies dans les couches intérieures pour acheminer le service à l’utilisateur.
Il faut souligner que le sens des dépendances ne peut aller que de l’extérieur vers l’intérieur, qu’importe le niveau de profondeur. L’UI peut dépendre de l’interface d’un objet du domain model sans pour autant passer par une encapsulation au niveau domain services ou application services
Pour utiliser les éléments d’une couche externe il suffit de l’abstraire sous forme d’interface par exemple, puis de la concrétiser dans un cercle extérieur.

En 2003 Eric Evans présente une approche de la conception centrée sur le domain model qui représente l’ensemble des règles métier du SUD. Il met principalement l’accent sur le fait d’utiliser un lexique commun entre les équipes de développement, les experts du domaine, et l’implémentation. Ce qui a pour effet de créer une norme naturelle pour définir le modèle.
Le DDD prône une première analyse stratégique du domaine, en identifiant le domaine cœur du système, puis les domaines périphériques et de support. En divisant éventuellement ces domaines en sous-domaines. Qui sont une représentation de la distribution des responsabilités du système au travers du lexique commun.
Puis une représentation du système sous forme de bounded contexts. Les bounded contexts sont des sous systèmes bornés, isolés et cohérents, qui sont la représentation du domain model dans un contexte particulier.
Une fois la phase d’approche stratégique accomplie, le DDD propose une série de patterns d’implémentation pour mettre en pratique l’isolation et la modélisation. (Malheureusement c’est cette dernière que la majorité des lecteurs auront retenu, l’analyse stratégique passe souvent inaperçue).
Uncle bob parle de clean architecture pour désigner une architecture qui respecte certaines propriétés :
Les différentes propositions que nous avons passé en revue ont beaucoup de points communs. Ce sont les propriétés essentielles véhiculées par ces architecture que nous cherchons à obtenir.
Le métier d’une application peut être souvent la partie la plus difficile à saisir, surtout pour un nouveau développeur.
L’aspect métier d’une application est bien souvent suffisamment complexe pour qu’on ne veuille tenter de brouiller les pistes davantage. Faire une place au business dans la base de code semble légitime.
L’analyse stratégique du business est indispensable à la mise en œuvre de ces méthodes. Déterminer le core domain du SUD puis identifier les différents bounded contexts. Décliner les différents use cases d’une application et les différentes entities qui composent le domaine métier de l’application. C’est la phase minimale : inutile d’aller plus loin sans passer par celle-ci. Le code devra refléter ces règles métier, il deviendra plus évident d’en comprendre la raison d’être.
Chacune des propositions précédentes oriente vers une étude préalable des responsabilités des systèmes et sous-systèmes.
Très présent dans le DDD, et dans les préconisations d’Uncle Bob, le lexique utilisé pour communiquer, modéliser, coder, et échanger des données, doit être commun, unique, connu et partagé entre toutes les équipes qui travaillent sur le projet et les experts du domaine.
Si des services doivent coopérer dans un domaine, ils le feront d’autant plus facilement si le langage employé pour communiquer est celui du domaine. Si le domaine venait a évoluer, son langage avec et donc la coopération entre les différents services du système pourrait le refléter naturellement.
Pour que la maintenabilité et l’évolutivité soient préservées, il faut s’attacher à la lisibilité du système à toutes les échelles.
Lorsque la terminologie du domaine est employée pour designer les composants logiciels, classes, services, fonctions, il devient rapidement plus évident pour chacun d’identifier les fonctionnalités globales de l’application.
Revenons à l’aspect monolithique d’une application. Plutôt que de mentaliser notre application comme un amas de code et de patterns imbriqués, il nous est possible de raisonner en terme de modules exposant un jeu de fonctionnalités dont le domaine fonctionnel est restreint.
On retrouve alors une architecture qui peut s’apparenter à de l’orienté composant ou au microservices à la mode. À l’exception que ces derniers sont sensés être des composants dont l’interface de communication se fait par l’extérieur du processus.
Quand je modifie ou implémente une fonctionnalité dans le périmètre d’un composant, je peux me contenter de raisonner à l’échelle de mon composant, tant que je ne touche pas à son interface. Ce qui nous mène à l’isolation.
Une bonne maîtrise des effets de bord du code impacté permet de développer en toute confiance. Nos modules de code doivent exposer des frontières explicites là où transitent les informations.
Ne passer que des structures de données en entrée et sortie de nos modules permet de rationaliser l’information. Ils deviennent donc plus faciles à tester car les données sont faciles à simuler. Mais il nous évite aussi de créer des dépendances accidentelles, si nos modules consomment des objets, il faut connaître leurs API, donc dépendance.
Avec l’isolation nous avons commencé à nous prémunir des dépendances. Nous devons quand même aller un peu plus loin et faire en sorte d’en finir avec le couplage et la dépendance. Faire usage d’abstraction, de composition, d’injection de dépendances pour inverser les dépendances au business et au framework.
Celui qui consomme est celui qui est dépendant. Pour que nos composants métier soient indépendants il faut que ce soit le framework qui consomme le module métier.
Notre application bénéficiera alors d’une grande capacité d’adaptation. Elle pourra même être « consommée » par un autre composant en tant que dépendance.
Les chemins pour parvenir à une application dont l’architecture du code est simple, flexible, évolutive, et « Agile » sont pluriels. Les propriétés précédentes vont dans le sens des vertus que nous recherchons.
Pour achever cet objectif il faut se discipliner à avoir un design cohérent, et éviter de multiplier les solutions pour un problème identique. Faire usage d’un nombre limité de patterns, technologies, dépendances.
Quelque soit la taille de notre système il sera composé également de sous-systèmes qui sont également composés de sous-systèmes… Travailler sur des petits composants sera beaucoup plus simple que sur un gros système monolithique. Ces sous-systèmes doivent être des modules indépendants, isolés, avec des interfaces connues et clairement définies. Ils seront donc plus simples à appréhender, mais aussi à tester et à documenter.
Le chemin qui mène à la flexibilité de l’architecture commence par une bonne segmentation des responsabilités du code ; diviser le système en composants aux responsabilités distinctes permet de les combiner librement.
L’adoption de la terminologie métier et de son modèle, pour structurer les interactions et objets au sein du code, permet d’appliquer plus facilement un changement dans les processus réels du métier.
En faisant usage d’abstraction (avec parcimonie) il devient très simple de modifier l’implémentation. La probabilité en est accrue.
Les interfaces des composants doivent rester minimalistes, efficientes. Plus une interface est complexe et confuse et plus les composants s’appuyant dessus risqueront de développer une dépendance.
L’architecture saine est adaptée aux besoins actuels. Sur-anticiper les besoins futurs monopoliserait des ressources pour résoudre des problèmes que l’on n’a pas encore, et que l’on ne rencontrera peut-être jamais.
Elle doit donc être capable d’évoluer sans encombre pour s’adapter demain aux besoins de demain (oui oui, demain c’est demain…). D’où l’importance de veiller au fait que les composants doivent être isolés, agnostiques de tout frameworks, SGBD, ou autre composant. Si l’un d’eux devient obsolète il sera simple de s’en séparer et de le remplacer par un plus performant ou plus adapté au besoin. Il devient aussi plus simple de modifier une implémentation tout en conservant la précédente, et donc de faire du refactoring progressif, de la rétrocompatibilité.
Le travail sur des composants isolés permet des cycles de livraison courts. Une base de code qui s’adapte, va dans le sens du changement.
Nous avons rapidement parcouru la problématique, les solutions, et une synthèse non exhaustive.
Normalement arrivé à ce stade, soit vous êtes familier avec le sujet et cette longue introduction peut être frustrante. Soit vous ne connaissez que peu le sujet, vous ne devriez pas y voir plus clair, et vous commencez à désespérer.
Il y a tant de choses à dire sur ces sujets, il faut bien commencer par un bout. Et c’est à partir d’ici qu’on entre dans quelque chose de concret, accompagné d’exemples.
Pour implémenter des systèmes découplés, évolutifs, testables, substituables… Il faut pouvoir dans un premier temps établir un cartographie de leurs pans fonctionnels.
Cette cartographie sert à établir la base de la terminologie et de la communication entre les équipes intervenant sur le système. Elle permet également d’avoir une vue d’ensemble du domaine du problème.
Elle sera le plus souvent au cœur des discussions qui interviennent en amont et en aval des chantiers de développement. Pour cela aussi il faut lui porter la plus grande attention.
Puisque le métier est au centre de l’architecture, l’étape la plus importante de la démarche est l’analyse du métier. Si cette étape n’est pas respectée et réalisée avec tout le soin et le sérieux qu’elle mérite, il deviendra bien plus difficile par la suite de structurer le code qui en découle.
Il est capital d’intégrer que les propriétés et vertus que nous recherchons ne viennent pas de l’implémentation ou des patterns employés à l’échelle tactique.
La clé se situe dans la compréhension du domaine, des différentes entités qui le composent, et de leurs relations.
Il ne serait pas possible de vous exposer les cas réels sur lesquels nous travaillons, pour des raisons de confidentialité, mais surtout parce qu’il vous faudrait en assimiler le domaine métier. Et dans certain cas, il faut plus d’un an !
Nous allons imaginer que nous travaillons pour une société qui développe un produit de gestion de projet dont la couverture fonctionnelle est proche de celle de Redmine.
Le domaine de la gestion de projet vous est sûrement plus familier que celui de la revente d’infrastructure opérateur par exemple.
Le cheminement à suivre commence par la définition du domaine de l’application ou du composant sur lequel on intervient. Je vais rester sur la terminologie DDD, car elle est précise et documentée.
La définition du domaine se fait assez naturellement en échangeant avec le donneur d’ordre. Le domaine global du système est l’environnement composé de l’ensemble des éléments et processus métiers qui interagissent pour fournir la valeur ajoutée.
Il correspond à l’énoncé du problème que l’on cherche à résoudre, et ne doit pas être encombré de relations à la solution mise en œuvre.
Si nous reprenons notre exemple :
Le domaine principal de notre commanditaire est celui de la gestion de projet. Il s’agit de la problématique. Le SUD est un outil de gestion de projet. Qui est la solution.
Le système peut et doit dans la grande majorité des cas être divisé en sous-ensemble fonctionnels. Cette première segmentation est d’une grande importance, car elle va nous donner une vision d’ensemble de la modélisation du domaine.
Soyons réalistes, dans un système complexe, utiliser un modèle complet pour dialoguer avec les équipes n’a rien de pratique. Il semble déjà difficile d’établir une telle cartographie, sans qu’elle soit obsolète le jour de sa parution.
C’est à cet effet qu’une cartographie de haut niveau, orientée métier, peut être une bonne base pour la suite de nos travaux et échanges avec les équipes.
Cette énumération des différents sub domains s’accompagne d’une classification de ceux-ci en fonction de leur rôle dans l’ensemble du système. Ainsi on peut identifier à minima :
Revenons à notre exemple.
Si on analyse le métier de l’application en compagnie des experts du domaine, et que dans un premier temps on essaie de découvrir quels sont les différents services fournis par le système, on ressort avec une liste équivalente à celle-ci:
Je limite les fonctionnalités volontairement pour rester succinct (oui, c’est déjà trop tard).
Les experts du domaine métier vous diront sûrement que le rôle principal de l’outil est de gérer le suivi, la planification de tickets au sein d’un projet et qu’il dispose de fonctionnalités visant à faciliter la vie des projets comme l’édition collaborative et la communication.
Bingo ! On vient d’identifier le core domain , et d’autres sub domains.
Le domaine du système est composé de sous-domaines:
En quelques minutes nous venons de découvrir la cartographie des domaines du SUD Ça ne vaut pas le coups de s’en passer. Ok, mais on en fait quoi ensuite ?
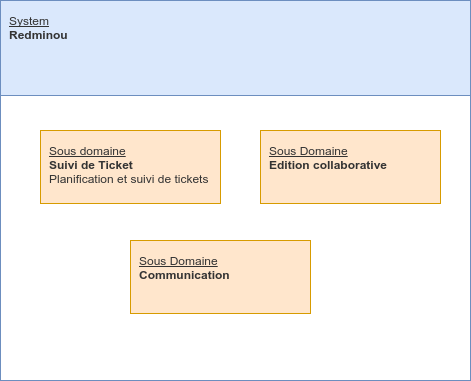
Si nous les catégorisons avec l’équipe métier, nous pourrions tomber d’accord pour définir que « Planification et suivi de tickets » est la fonctionnalité cœur du système. Et donc le core domain du moment! (Dans la vie d’une entreprise ça peut évoluer).
Ensuite l’édition collaborative et la communication viennent en soutien aux projets, il seront donc identifiés comme supporting domain. Car ils ne sont pas essentiels à la réalisation de l’objectif, mais viennent compléter le métier principal.
Cependant nos interlocuteurs du métier n’ont pas mentionné la partie authentification. C’est assez probable, car ça n’entre pas dans leurs considérations quotidiennes de gestion de projet. C’est avec l’expérience et l’intuition que l’on peut identifier certains sub domains manquants en amont.
Le domaine de l’authentification est quelque chose de générique qui peut s’appuyer sur un fournisseur tiers éventuellement. Il n’est pas directement en lien avec le cœur de métier, nous l’identifierons comme generic subdomain.
Mais le generic subdomain des uns peut être le core domain des autres. Prenez le cas de Auth0 pour exemple.
Notre cartographie mise à jour fait maintenant mention de l’authentification.
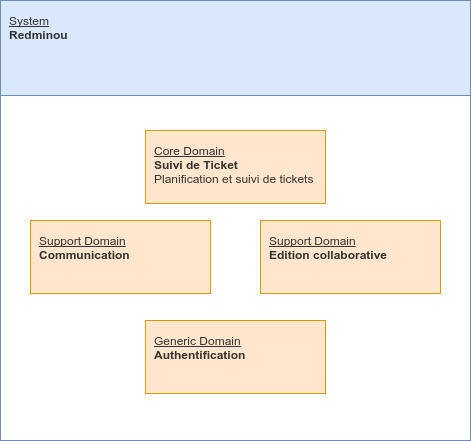
Le piège de cet exemple est que le cas est simplifié. Pour obtenir la cartographie complète d’un système d’information ça prendra bien plus d’une phrase !
Il est important que le travail sur cette cartographie soit un processus continu. Que les entrevues avec les acteurs experts du métier, les opérationnels, et les développeurs soient fréquentes et utilisent cette cartographie comme base pour la maintenir et l’enrichir.
Il est possible qu’arrivé ici vous n’ayez pas l’impression d’avoir gagné grand chose… Cependant considérons l’aspect stratégique que l’on peut dériver de la vue stratégique:
Le domain identifié comme core domain est critique. C’est par lui que je vais commencer les analyses plus profondes. Je vais y affecter mes meilleurs experts métier, et mes développeurs les plus expérimentés. Ce domaine est prioritaire dans beaucoup de prises de décisions, comme l’allocation de ressources (jours/homme, matériel, budget), ou la réactivité opérationnelle.
Les supporting domains auront une priorité inférieure à notre core domain. Je pourrais y placer des développeurs moins expérimentés pour les former, ou même envisager l’outsourcing. Je pourrais me donner un peu plus de flexibilité sur la qualité (code, tests, documentation). Ou éventuellement tenter quelques expérimentations techniques. Avoir une priorité moindre sur les demandes de support, et ainsi de suite.
Et pour finir les generic domains, un peu comme les supporting domain. Mais pour ces domaines on peut sûrement envisager d’utiliser un service tiers, d’intégrer ou développer des solutions libres ou open source.
Ce ne sont que des exemples, suivant le contexte, l’outil d’analyse peut donner des résultats différents. L’analyse nous permet d’identifier des stratégies qui vont permettre de piloter le projet. Bien placer ses ressources et ses priorités n’a rien d’automatique. Cette phase initiale, dont le rendu graphique nous semble si insignifiante n’est-elle pas un facteur majeur de l’issue du projet ? Est ce que ça vaut le coup de s’en passer ?
Cette distribution fonctionnelle est le partitionnement du système à l’échelle macroscopique. Elle va nous permettre d’exprimer précisément les modèles qui interviennent dans chaque grand domaine du système. Elle sera surtout la base de réflexion pour identifier comment distribuer mon application sur plusieurs nœuds, équipes, technologies, dépôts de source…
Dans le prochain article de la série nous nous intéresserons davantage à la solution, en identifiant les bounded contexts et leurs relations.
L’équipe Synbioz.
Libres d’être ensemble.
